[Big Data, Coherence] Hadoop MapReduce and Coherence - A Perfect Match
Senin, 18 November 2013
0
komentar
https://blogs.oracle.com/OracleCoherence/entry/hadoop_mapreduce_with_coherence
Hadoop MapReduce (M/R)は、HDFSクラスタ上で大規模データセットを並列・分散アルゴリズムを使って処理するための最も人気のあるプログラミングモデルです。
Hadoop MapReduce(リンクはチュートリアル)Coherenceは業界をリードするインメモリデータグリッドです。Hadoopはバッチで処理できる、(テラバイト以上のデータを扱うような)大規模な処理操作に対して強みを発揮するのに対し、Coherenceは、よりリアルタイムの処理が必要で、かつデータ量が小さい場合には、データ保持においてHDFSよりも強みを発揮します。
http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
そんなわけで、Hadoop M/Rについて詳しくなろうと思ったのですが、両者を組み合わせるのはそれほど難しくないはず、と認識しました。以下で提示するソリューションは、標準的なHadoop M/R APIを使って、あたかもHDFSクラスタ上に保存されているかのようにCoherenceデータグリッドに格納されているデータを処理する、というものです。HadoopのWordCountサンプルだと以下のようになります。
元のHadoopサンプルから変更したのは、CoherenceInputFormatとCoherenceInputFormatクラスを使い、入出力パスをHDFSではなくCoherenceキャッシュにした、という点だけです。その他は全て、ユーザー定義のMapクラス、Reduceクラスを含めて、Hadoop M/R APIと同じです。このM/Rジョブを実行するために、Hadoopクラスタを構築・実行する必要はありません。必要なものはCoherenceクラスタです。import com.oracle.coherence.mapreduce.JobClient;
...
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("coherence-wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(CoherenceInputFormat.class);
conf.setOutputFormat(CoherenceOutputFormat.class);
CoherenceInputFormat.setInputPaths(conf,new Path("coherence://wordcount-Input");
CoherenceOutputFormat.setOutputPath(conf,new Path("coherence://wordcount-Result"));
RunningJob job = JobClient.runJob(conf);
Under the Hood
まず、Entry ProcessorsとAggregatorsはmapperとreducerを実装する上で自然な選択のように見えますが、両者には結果を導くために一つのメンバー/スレッドを必要としますので、mapper/aggregatorの結果セットが一つのメンバーヒープにフィットできる場合に限って、このソリューションを適用することができます(詳しくは、Christiona FeldeのCoherenceとM/Rに関するすばらしいエントリをご覧下さい)。Oracle® Coherence Developer's Guide Release 3.7.1この制限を回避するため、このソリューションでは分散起動サービス(Distributed Invocation Services)をメンバーアフィニティと共に利用し、MapperとReducer機能を実装します。
Performing Transactions
Using Entry Processors for Data Concurrency
http://docs.oracle.com/cd/E24290_01/coh.371/e22837/api_transactionslocks.htm#BEIJCGDF
Processing Data In a CacheData Grid Aggrigation
http://docs.oracle.com/cd/E24290_01/coh.371/e22837/api_processcache.htm#CHDFFFEI
Oracle® Coherence開発者ガイド リリース3.7.1
トランザクションの実行
データの同時実行性のための入力プロセッサの使用方法
http://docs.oracle.com/cd/E26853_01/coh.371/b65026/api_transactionslocks.htm#BEIJCGDF
データ・グリッドの集計
http://docs.oracle.com/cd/E26853_01/coh.371/b65026/api_processcache.htm#CHDFFFEI
Oracle Coherence and MapReduce (Blog of Christion Felde)
http://blog.cfelde.com/2012/12/oracle-coherence-and-mapreduce/
Oracle® Coherence Developer's Guide Release 3.7.1これにより、2個の起動サービスとCoherenceキャッシュ上のいくつかのHadoopインターフェースの実装だけが問題になりました。
Processing Data In a Cache
Node-Based Execution
http://docs.oracle.com/cd/E24290_01/coh.371/e22837/api_processcache.htm#CHDGJJEI
Oracle® Coherence開発者ガイド リリース3.7.1
キャッシュ内のデータの処理
ノードベースの実行
http://docs.oracle.com/cd/E26853_01/coh.371/b65026/api_processcache.htm#CHDGJJEI
 |
| Fig-1 |
JobClient
Hadoopでは、JobClientはユーザーのジョブがクラスタと対話するための主要なインターフェースです。JobClientはジョブの発行、進捗の追跡といった機能を提供します。通常ユーザーはアプリケーションを作成し、ジョブの様々な側面をJobConfを使って設定し、JobClientを使ってジョブを発行し、その進捗を監視します。JobConf (Apache Hadoop Main 2.2.0 API)このソリューションはJobClient Hadoopクラスの独自実装を提供します。Mapフェーズの入力データは既にCoherence InputCacheに格納されていることを想定しています。JobClientはその作業をMapperサービスとReducerサービスの実行を調整するRunningJobクラスに委譲します。Mapper、Reducerとも、JobInfo Coherenceキャッシュを通じて進捗やステータス情報を通信します。
https://hadoop.apache.org/docs/stable/api/org/apache/hadoop/mapred/JobConf.html
MapperService
MapperServiceはCoherence非同期実行サービス(Coherence Async InvocationService)として実装されています。これはCoherenceクラスタの全てのストレージが有効なメンバー上で動作します。データ処理の現場で実装するためには、MapperServiceを実行する各メンバーは、CoherenceRecordReaderを使って、そのメンバーに格納されているInputCacheエントリのみを処理します。MemberPartitionsListenerを使って、クラスタメンバー毎のParitionSetの経過を追跡し、PartitionFilterを使って関連するローカルエントリのみを取り出します。<distributed-scheme> |
| Fig-2 |
このMapperOutputCacheは、同じ送出されたキーを持つ全てのエントリが同じパーティションに格納されるようにPartition Affiinyを使って構成します。Partition Affiinyを持つことで、Reducerを実行する前にサイドデータをシャッフルする必要がありません。
OutputCollectorは、MapperUniqueKeysCacheに送出された各々の一意なキーに対するエントリも作成します。MapperCacheと同様に、マスタエントリやMapperCacheエントリに関連する全てのエントリが同じCoherenceパーティションに格納されるよう、MapperUniqueKeysCacheは同じ関連キーで定義されたPartition Affinityを持っています。
ユーザ定義のCombineクラスをジョブに設定すると、OutputCollectorはMapperCacheへバッファをフラッシュする前にローカルでCombineクラスを適用します。これにより、reducerが処理するエントリの個数が減ります。
ReducerService
ReducerServiceははCoherence非同期実行サービス(Coherence Async InvocationService)として実装されています。これはCoherenceクラスタの全てのストレージが有効なメンバー上で動作します。サービスの各インスタンスは、サービスインスタンスを実行するメンバーにローカルに格納された中間キャッシュエントリを削減するだけです。ReducerServiceはMapperがMapperUniqueKeyCacheに送出した一意なキーのリストを反復処理します。各々の一意なキーについて、KeyAssiciatedFilterを使い、同じ一意のキーを持つ全てのMapperOutputCacheエントリを発見します。結果セットをHadoop OutputCollectorクラスのCoherenceベースの実装と共にユーザー定義したReduceクラスに渡します。その後、ReduceクラスはOutputCollectorを使い、(透過的に)結果をCoherenceのResultCacheに送出します。
 |
| Fig-3 |
Installing the demo
デモソリューションを2個用意しました。一つはWordCount、もう一つはStandardDeviationです。サンプルを実行する方法は以下の通りです。- ソリューションをダウンロードしZipファイルを展開します。
- ソリューションには全ての依存関係のあるjarファイルがlibディレクトリに入っています(hadoop、coherenceなど)。
- setEnv.cmdを編集し、関連する環境変数を変更します。
- cache-server.cmd scriptスクリプトを実行し、1個以上のCoherenceキャッシュサーバーを立ち上げます。
WordCount Sample
WordCountは最も有名なMapReduceのサンプルです。このサンプルはまず、テキストの約100,000行をキャッシュに取り込みます。Mapperは行をトークンに分割し、キーとして単語、値として1を持つキー・バリューのペアを送出します。Reducerは同じ単語について全ての1を集約します。サンプルを実行するには、run-wordcount.cmdを実行します。
2013-11-13 23:27:10.868/16.038 Oracle Coherence GE 3.7.1.1 <Info> (thread=Invocation:InvocationService, member=5): CoherenceMapReduce:JobId=1660803 JobClient:ReducerObserver - Member 1 Completed : Machine=MBENOLIE-IL Process=8148
Job Completed
**** Job Summary:
**** Job Id: 1660803
**** Job Name: wordcount
**** Mapper ****
------------Input Cache Size: 100000
------------Duration: 4036 ms
**** Reducer ****
------------Intermediate Cache Size: 162164
------------Unique Entries Size: 11108
------------Duration: 3964 ms
Standard Deviation Sample
Standard Deviationサンプルは、これも有名なサンプルの一つで、MapReduceを使い、図4の式に基づいてサンプルの標準偏差を計算します。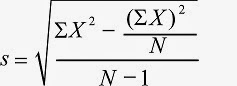 |
| Fig-4 |
サンプルの各値に対して、MapperはX(値そのもの)、X2、そして数1の三個からなる値を送出します。Reducer/Combinerは送出された値を足しあわせ、N、sum(X2)、(sum(X))2の結果エントリを作成します。
サンプルを実行するには、run-stddev.cmdスクリプトを実行します。次のような出力が出てきます。
2013-11-13 23:44:55.818/6.953 Oracle Coherence GE 3.7.1.1 (thread=Invocat ion:InvocationService, member=6): CoherenceMapReduce:JobId=114742004 JobClient:R educerObserver - Member 1 Completed : Machine=MBENOLIE-IL Process=8148
Final Calculation : entries in outputcache=3
Count = 20000.0
Sum = 1327351.1950964248
Sum of Sqrt = 8.83890996020529E7
Job Completed
Standard deviation= 3.8474319265580275
**** Job Summary:
**** Job Id: 114742004
**** Job Name: StandardDeviation
**** Mapper ****
------------Input Cache Size: 20000
------------Duration: 313 ms
**** Reducer ****
------------Intermediate Cache Size: 60
------------Unique Entries Size: 3
------------Duration: 51 ms
Tracking the M/R jobs
非常に原始的なコンソールを提供しています。console-mapreduce.cmdスクリプトを実行してコンソールを起動します。このコンソールを使い、ジョブの進行状況を追跡し、ジョブの結果(つまり数えた単語のリスト)を表示することができます。Summary
既存のM/Rアセットを維持しつつ、開発者に最も適切なデータストアの選択の自由を提供して、既存の強力なCoherenceの機能を活用して、ソリューションはCoherenceインメモリ・データ・グリッドのリアルタイム/Fast Dataの性質と、人気のあるHadoop MapReduce APIを結びつけています。TERIMA KASIH ATAS KUNJUNGAN SAUDARA
Judul: [Big Data, Coherence] Hadoop MapReduce and Coherence - A Perfect Match
Ditulis oleh Unknown
Rating Blog 5 dari 5
Semoga artikel ini bermanfaat bagi saudara. Jika ingin mengutip, baik itu sebagian atau keseluruhan dari isi artikel ini harap menyertakan link dofollow ke http://apk-zipalign.blogspot.com/2013/11/big-data-coherence-hadoop-mapreduce-and.html. Terima kasih sudah singgah membaca artikel ini.Ditulis oleh Unknown
Rating Blog 5 dari 5




0 komentar:
Posting Komentar